Disclaimer: This article is about Visual Studio Team Services (VSTS) and GitHub. The author has a very positive opinion about both services and does not get any offers from Microsoft or GitHub writing this article. The whole article is written IMHO.
Over the last years GitHub has become a success factor for projects related to git repositories for me personally. I also tested several other solutions but mainly I struggeled with the performance or the usability. About 2 years ago I started using Visual Studio Team Services (VSTS) with a work related project. The service looked promising but had a lot of early release issues, so in the last 24 months it was interesting to see how a promising solution became adult. Last week I decided to move away from GitHub for all my closed source projects and rely on Visual Studio Team Service (VSTS). This article gives a deeper look on the main reasons of why I did the move and may help deciders to get detailed information before implementing:
Git-Repository sprawl
Nowadays thanks to bower, npm, bundler or NuGet the amount of Git repositories are growing steadily. When you are focused on component based software development Git is a great helper but the amount of repositories is sprawling because very often every component has its own live in a separated Git repository, which means you have a separate release cycle and a different versioning compared to your main project.

I guess this is the secret source of component managers which are working closely together with git repositories. Of course VSTS and GitHub are supporting multiple git repositories but GitHub lets you pay on a package on git repositories, VSTS lets you pay for users. Especially for small teams paying for users is the better deal, compared to paying for repositories. At the end Microsoft offers a smaller groups of 5 everything for free. This fact stopped my permanent GitHub problem: Having too less private repository space.
GitHub:
O – Allows to have as many GitHub repositories as needed
+ – Generates releases out of tags automatically (good semver integration)
– – Charging base is the count of private git repositories
VSTS:
O – Allows to have as many GitHub repositories as needed
+ – Comes with unlimited git repositories, plans are user based
– – Repository management is not that intuitive as it is in other solutions
Pull Requests and Forks
Forks and pull requests are the most important features GitHub introduced very early to support community driven development. I would say in the open source world Github is the platform when it comes to forks and pull requests. Currently I would never think about moving open source repositories away from GitHub because of this great feature.

When it comes to closed source projects, forking and pull requests are becoming only important in bigger teams with different products or product lines. We are using this feature strongly in our teams at my company. Smaller startups or teams will not use these workflows often but nevertheless it is a road blocker for me to do the 100% switch to VSTS. I guess it took Microsoft around 12 month to deliver it in a more simple way GitHub is doing this.
GitHub
+ – Cross repository forking
+ – Pull requests incl. discussion thread and a lot of community features
VSTS:
O – Supports pull request on repository level
Agile Process support with EPiCs, features and backlogs
When it comes to bigger teams or more structure, people are having the option that to implement a process is the key. This brings me to the biggest enterprise blocker I see in GitHub, the Issue-Tracking system. Companies who migrated to an agile framework like SCRUM or KANBAN need to have the option to work with features, backlogs or bugs. Microsoft delivers with VSTS a highly customizable and adaptable work item management system. The SCRUM and KANBAN template makes perfect sense for agile teams but also the traditional waterfall model can be implemented (even if I don’t understand why someone should do this.)
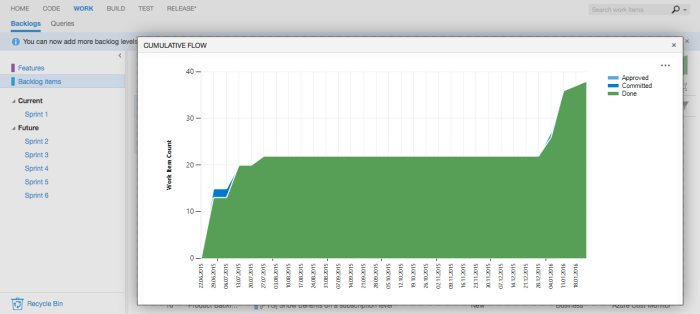
GitHub
– – It’s just an Issue Tracker
+ – Has good integration into many cloud services
VSTS:
+ – Offers customisable work item management
+ – Comes with templates for agile team structures
Handle your Test-Cases
Even if your projects comes with a great code coverage and good unit tests, the requirements to execute manual tests or just to orchestrate automated integration tests exists. VSTS implements based on the work item management a test case management which has the option to integrate it with automation bots via WinRM and other protocols.

The ability to document test cases and write specific step by step guides how to verify a feature is a big plus esp. in small teams where no dedicated QA resources are hired.
GitHub
O – Ability to integrate with external QA services
– – No integrated test case management
VSTS:
O – Ability to integrate with external QA services
+ – Test Case management is part of the work item management
Centralised Source Code management as migration path
For a couple month Microsoft offers virtual TFS collection, which allows companies that want to go pave the road for git based repositories to stay with the existing centralised source code management besides new git repositories. In the early day VSTS just supported a TFS collection per project space but now maintaining TFS collection is that easy as it is creating new git repositories. This will become very important features for existing TFS customers.
Revised Build-System incl. Linux Support
I guess Microsoft learned very fast that the XAML file based build system was very inflexible and complicated for a SaaS service like VSTS. Because of that a couple month ago a new step based build system was introduced which will orchestrate the build agent out of VSTS
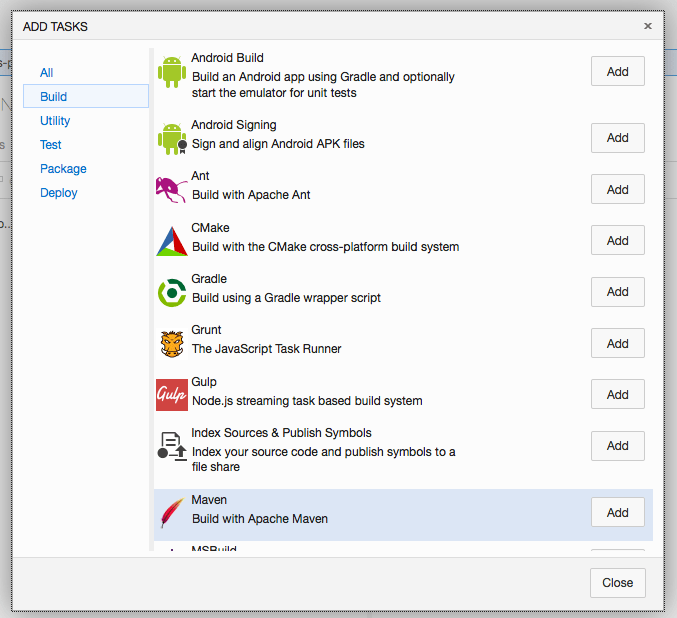
Since Microsoft supports Windows, Linux and Mac build agents there are no road blockers anymore, besides that the hosted build services for VSTS are very rare. There is a build server Microsoft offers out of the box but from my experience you will get more problems customizing that. When you are focused on Azure check also what the Azure App Services can do for you because KuduSync offers out of the box build for your .NET application during deployment.
GitHub
+ – Many different build services available with GitHub integration (CodeShip, T..)
– – Build definitions are not part of the code project
– – No release management to aggregate several projects
VSTS:
– – Hosted build services for VSTS rare
+ – Build definitions are part of the code project
+ – Release Management allows to aggregate several sub projects
Other services and options:
There are also other options and products on the market and I guess one of the most popular one is Assembla which is pretty comparable to Visual Studio Team Services. Also the products from Atlassian (Jira, BitBucket) are great options supporting your development cycle. This article had the intention to support companies who are dealing with GitHub and / or On Premise TFS and now are thinking about combining the positive of both.
I personally think GitHub could become a great option for enterprises as well, when the Issue-Tracker problem is solved which was mainly the reason why I searched for an alternative!