Azure Table Store offers a very important scalability feature which should be used when working with timelines. The partitionkey in every table allows Microsoft to put entities on different servers. Let’s recheck the limits of Azure Table Store to make a right decision (http://azure.microsoft.com/en-us/documentation/articles/azure-subscription-service-limits):
- Azure Table Store returns 1000 entities per page. If the result contains more entities the client needs to query several times -> A timeline service should never page to render the first timeline
- Azure Table Store returns 2000 entities with 1KB of size per second as a guaranteed SLA –> A timeline service should never request more data per page to stay performant
- Azure Table Store allows to store up to 500TB per storage account, it could be stored in one table or different –> A timeline service should be able to handle several storage accounts, at least theoretically.
With all this limitations in mind it’s possible to build a table structure for the timeline service as follows:
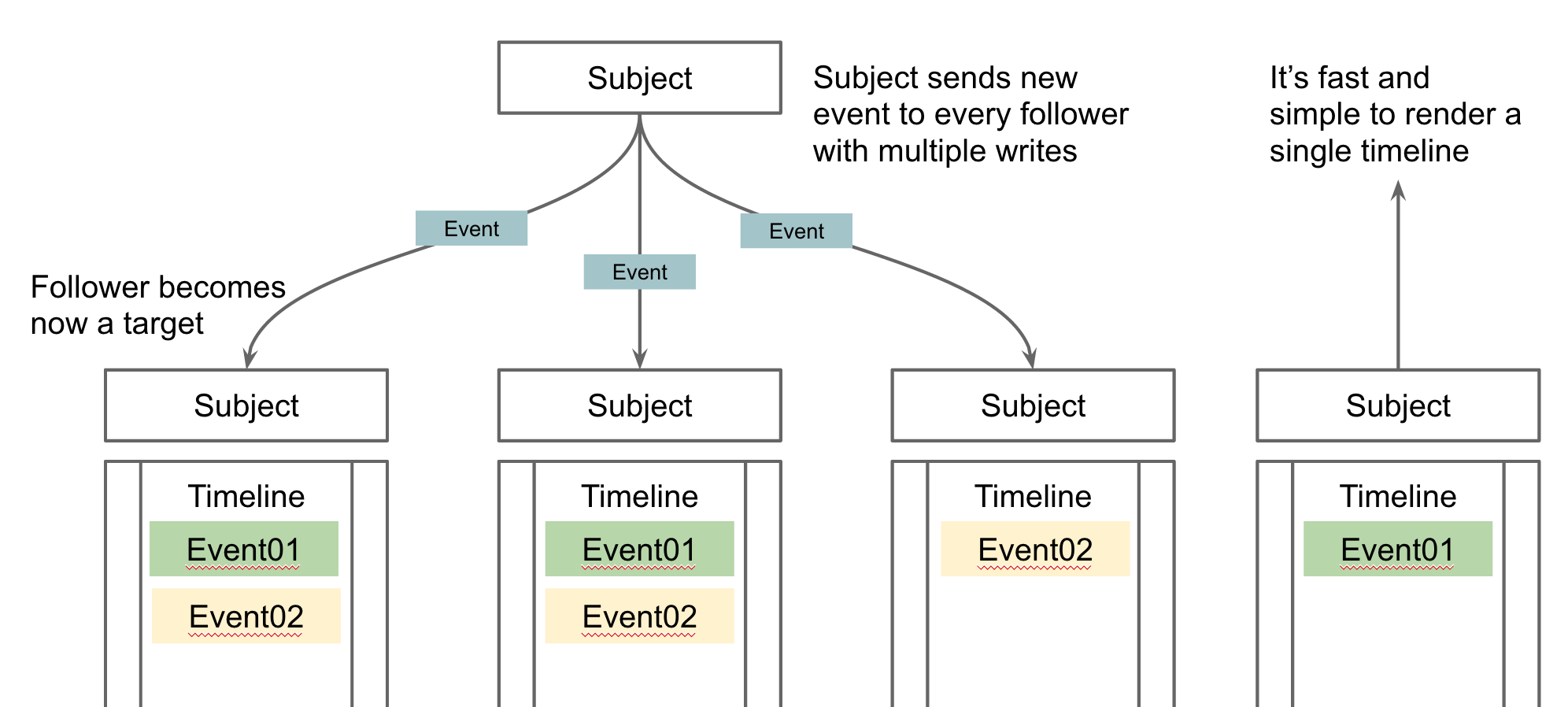
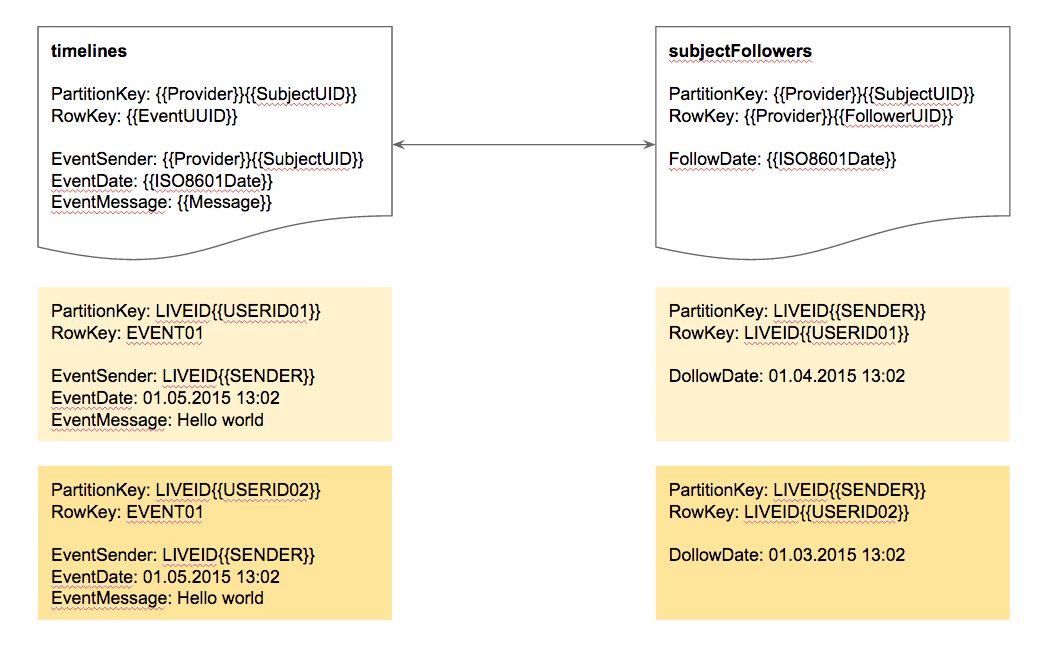
- timelines
The timlines table contains all timelines the system has registered. The partitionkey of this table is timeline identifier so every subjects timeline can be stored on different nodes. The partitionkey should be a key generated from the subjects identification, e.g. liveid{{UID of LiveId-Token}}. This prevents the system to lookup an other table to get the timeline identifier when the subject tries to render them.In addition the event which should be stored on several timelines can be identified by his event identifier as the row key. This allows the system to also implement removal jobs because a multiple stored event can be identified as the single one. - subjectFollowers
the subjectFollowers are a list of subjects following a specific subject. The partitionkey of this table is also the subject identifier so it’s easy to get all followers of a subject. In addition the row key becomes important because it identifies the subject who is following someone else. This gives a system the option to find all followers of a specific subject and all subjects a specific subject is following very fast. Works well in both directions.
This simple data structure allows the service to handle hundreds of different timelines and relations. Especially the background worker can now identify on which timeline the event needs to be stored.
Last but not least, when it comes to requesting the timeline content it will only be returned in pages of 250 elements to stay healthy with the performance. An other page can be requested at any time when the user starts paging.