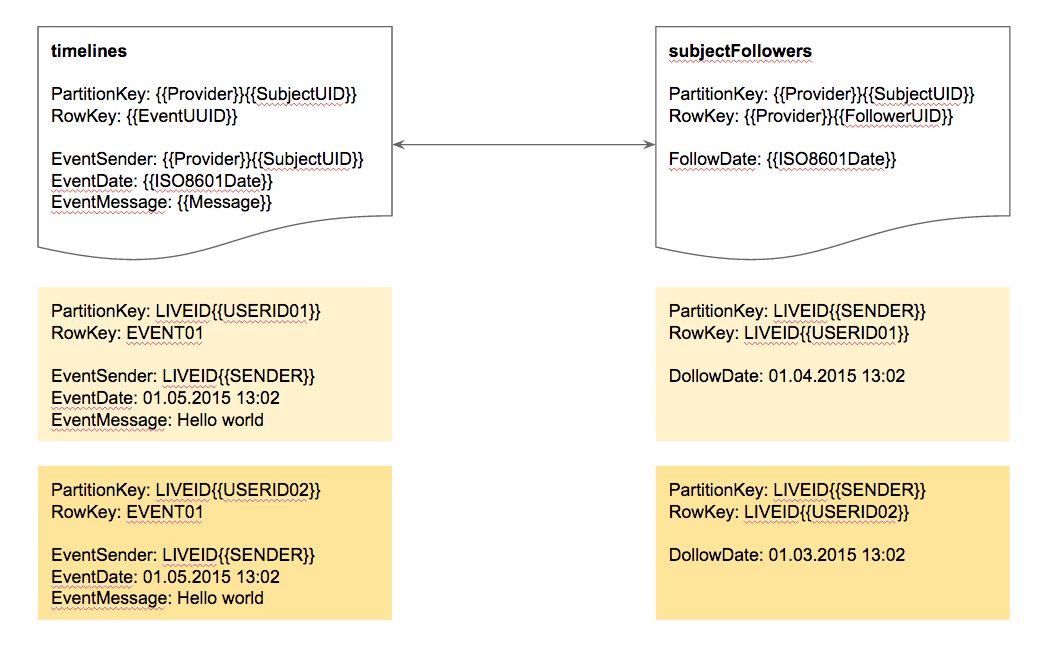
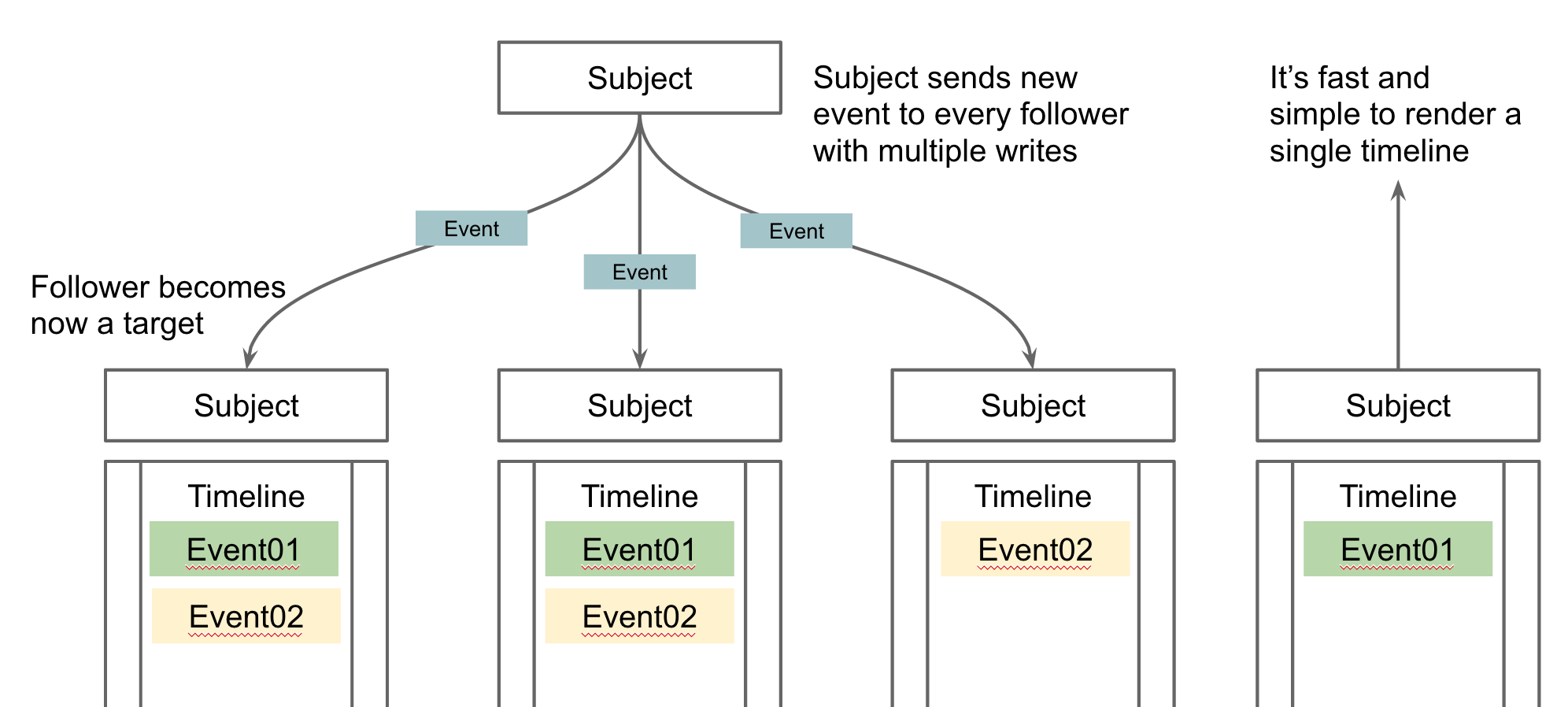
With Azure App Services (aka. Azure WebSites), the Microsoft Azure cloud offers a great, highly scalable and simple way to host cloud and SaaS services. Besides ASP.NET, several other platforms and languages are supported, e.g. node.js, Python or Java. I personally prefer hosting services written in node.js on this nice managed service of Microsoft.
A common problem for web-services are background jobs like e.g. sending out e-mails or calculating some sales numbers once a day. This use-case can be addressed with Azure WebJobs which are running on the same instance as the web service itself. Jamie Espinosa described the behaviour of WebJobs on an Azure Friday very well. Azure Friday is BTW hosting a whole series about Azure WebJobs, so check it out to get more information.
Normally when deploying a web service into the Azure WebSite the associated WebJobs will be restarted out of the box. A special thing of node.js based Azure WebJobs is that only when the run.js file is changed the WebJob will be restarted. This means when the system just changes an other module or updates the npm dependencies no restart will be enforced.
The whole deployment is based on the Kudu-Project and this project offers so called Post-Deployment-Action-Hooks to trigger a simple script right after the successful deployment of the sources. When ever the run.js file becomes touched the system just restarts the web service, so the solution for this deployment issue was to write a short batch which touches all run.js files:
@echo off echo Restarting all WebJobs for /R ..\wwwroot\App_Data\jobs %%G IN (*run.js) DO echo Touching %%G for /R ..\wwwroot\App_Data\jobs %%G IN (*run.js) DO touch %%G exit 0
This script can be registered as Post-Deployment-Action-Hook via FTP at every Azure WebSite. Just copy the file to the following location:
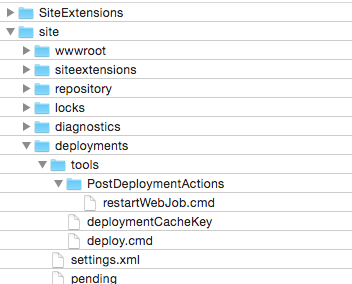
This works fine but after all there is still one piece missing: How to get the deployment hooks deployed with git themselves? There are several options to reconfigure the deployment hook directory but I was not able to figure this out. So when you have an idea, feel free and leave a message to discuss any options.